从pdd收了一张100不到的1060,超级牛逼,但是这货不支持视频输出,也不支持编解码。但是牛逼就牛逼在他真的和1060核心一样,久经沙场体质好对吧。(😆)
一开始看到了这篇文章,里面提到直接改vendorID和deviceID可能可行,然后从[这里]找到了1060的deviceID,在PVE里面直接填进去,然后去Windows里看了下,确实是1060了,驱动也装得上,但是就是调不起来,估计是驱动还是不太一样,然后就放弃了。
魔改驱动
发现了前辈的文章,这个里面有个魔改驱动,Windows下一键安装,直接就能用。测试后确实成功了。
打游戏
RDP效果炸裂,尝试了下Parsec,网络延迟10ms,解码4ms,编码60ms+++,还是软解码,然后一搜发现这个东西是不支持硬解码的,寄。
尝试MC,发现开光影和不开光影帧率全都稳定20帧,最后发现是服务器U不行,玩游戏U成了瓶颈(服务器U是E5-2650,讲究一个能用就行。
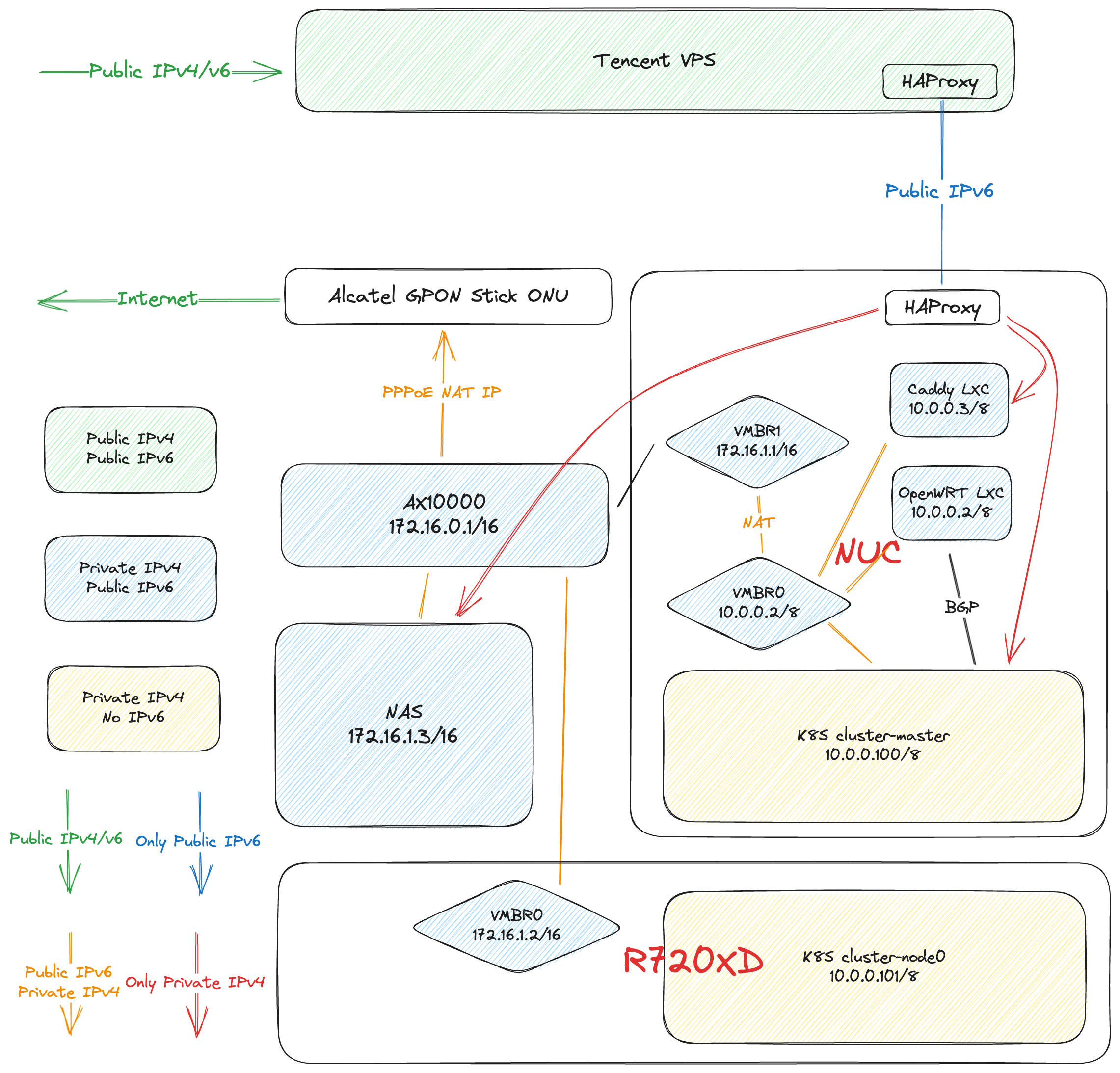
直通K8S
最后想到了还是通进linux里跑跑机器学习吧,然后就开始了漫长的折腾。
k8s官方确实给了文档:https://kubernetes.io/zh-cn/docs/tasks/manage-gpus/scheduling-gpus/,然后跟着这个去一步步安装,结果第一步就寄了。
nvidia-driver
我k8s宿主机用的Rocky Linux 8,centos系的,然后就跟着官方文档安装,一开始用的dnf装的,结果死都装不上,要么是报这种错
Error:
Problem 1: package nvidia-kmod-common-3:515.48.07-1.el8.noarch requires nvidia-kmod = 3:515.48.07, but none of the providers can be installed
- cannot install the best candidate for the job
- package kmod-nvidia-latest-dkms-3:515.48.07-1.el8.x86_64 is filtered out by modular filtering
- nothing provides dkms needed by kmod-nvidia-latest-dkms-3:515.48.07-1.el8.x86_64
- package kmod-nvidia-open-dkms-3:515.48.07-1.el8.x86_64 is filtered out by modular filtering
- nothing provides dkms needed by kmod-nvidia-open-dkms-3:515.48.07-1.el8.x86_64
要么是报这种错
asm/kmap_types.h: no such file or directory
前者不知道为啥,没办法装percompiled的,然后就只能装dkms-latest,但是好想和最新的kernel不兼容,缺少头文件。我rnm
最后看到了这个文章,里面提到了要440版本的驱动,然后我尝试了个470版本的runfile安装,终于成功了。(不知道为啥失败了,也不知道为啥成功了。
nvidia-smi
然后发现驱动打上了,设备驱动也有,但是就是报错
在dmesg | grep NVRM中发现了
[ 7.969112] NVRM: GPU 0000:01:00.0: RmInitAdapter failed! (0x22:0x56:667)
搜到了这个文章:https://forums.developer.nvidia.com/t/nvrm-rminitadapter-failed-proxmox-gpu-passthrough/199720/2
最后试了下这个成功了。

这个比较简单,跟着这个安装一下,就行,也不会失败
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
装完可以试一下
[root@cluster-node0 ~]# ctr run --rm -t --gpus 0 docker.io/nvidia/cuda:12.2.0-base-ubuntu20.04 nvidia-smi nvidia-smi
Wed Sep 27 08:18:40 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.199.02 Driver Version: 470.199.02 CUDA Version: 12.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA P106-100 On | 00000000:01:00.0 Off | N/A |
| 21% 35C P8 5W / 120W | 0MiB / 6080MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
大成功!
k8s-device-plugin
这个也不难,看这个文章就行
https://github.com/NVIDIA/k8s-device-plugin#quick-start
但是要记得跟着文档改一下配置,不是装完toolkit就行。
我用的helm安装的,基本就一键,贴一下我的配置,基本没改啥,
config:
name: ""
map:
default: |-
version: v1
flags:
migStrategy: mixed
sharing:
timeSlicing:
renameByDefault: false
failRequestsGreaterThanOne: false
resources:
- name: nvidia.com/gpu
replicas: 4
default: ""
fallbackStrategies: [ "named", "single" ]
legacyDaemonsetAPI: null
compatWithCPUManager: null
migStrategy: null
failOnInitError: null
deviceListStrategy: null
deviceIDStrategy: null
nvidiaDriverRoot: null
gdsEnabled: null
mofedEnabled: null
nameOverride: ""
fullnameOverride: ""
namespaceOverride: ""
selectorLabelsOverride: {}
allowDefaultNamespace: false
imagePullSecrets: []
image:
repository: nvcr.io/nvidia/k8s-device-plugin
pullPolicy: IfNotPresent
tag: ""
updateStrategy:
type: RollingUpdate
podAnnotations: {}
podSecurityContext: {}
securityContext: {}
resources: {}
nodeSelector: {}
affinity: {}
tolerations:
- key: CriticalAddonsOnly
operator: Exists
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
priorityClassName: "system-node-critical"
runtimeClassName: null
nfd:
nameOverride: node-feature-discovery
enableNodeFeatureApi: false
master:
extraLabelNs:
- nvidia.com
serviceAccount:
name: node-feature-discovery
worker:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Equal"
value: ""
effect: "NoSchedule"
- key: "nvidia.com/gpu"
operator: "Equal"
value: "present"
effect: "NoSchedule"
config:
sources:
pci:
deviceClassWhitelist:
- "02"
- "0200"
- "0207"
- "0300"
- "0302"
deviceLabelFields:
- vendor
gfd:
enabled: true
nameOverride: gpu-feature-discovery
namespaceOverride: ""
大成功,所有pod起来了就行。然后看下node的label,有没有标注上去
Name: cluster-node0
Roles: <none>
Labels: .......
nvidia.com/cuda.driver.major=470
nvidia.com/cuda.driver.minor=199
nvidia.com/cuda.driver.rev=02
nvidia.com/cuda.runtime.major=11
nvidia.com/cuda.runtime.minor=4
nvidia.com/gfd.timestamp=1695800061
nvidia.com/gpu.compute.major=6
nvidia.com/gpu.compute.minor=1
nvidia.com/gpu.count=1
nvidia.com/gpu.family=pascal
nvidia.com/gpu.memory=6080
nvidia.com/gpu.product=NVIDIA-P106-100-SHARED
nvidia.com/gpu.replicas=4
nvidia.com/mig.capable=false
nvidia.com/mig.strategy=mixed
......
Capacity:
......
nvidia.com/gpu: 4
大成功!
起pod
$ cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
EOF
看一下输出
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
大成功!
下班!!!
P.S.
CNM,�本来想跑个ollama的,结果告诉我illegal instruction,查了一下发现大部分模型都要avx2,然后我这个cpu不支持,寄。
服务器型号是R720XD,只支持E5-2600 v1,v2,但是avx2是v3开始支持的。寄。摆。